

Summary
At Nava Labs, we’re creating, testing, and piloting AI-powered tools that may help government agency staff and benefit navigators easily identify which families can enroll in key public benefit programs such as the Special Supplemental Program for Women Infants and Children (WIC), the Supplemental Nutrition Assistance Program (SNAP), and Medicaid. In order to better understand how AI-powered tools could expand access to public benefits, we conducted a series of human-centered experiments.
Approach
We began this project by conducting user research with stakeholders at every level of the benefits application process. This included professionals who help people apply for benefits—often called navigators—program beneficiaries, and strategic advisors from organizations in the public benefits space. You can read more about our user research in this case study.
Our research helped us identify some core needs that beneficiaries and navigators have throughout the application process. If those needs aren't being met, we considered it a potential use case for an AI-powered tool. For several of these use cases, we designed experiments to gauge whether AI models might help meet peoples’ unique needs. We also wanted to learn about the technical feasibility of building a working prototype of an AI-powered tool.
We regularly began our experiments by testing AI tools to see whether solutions exist for that use case. For the sake of simplicity and consistency, we scoped our initial experiments to focus on SNAP program rules. Early on in the project, we decided that all of our experiments would keep a human in the loop, meaning that navigators will vet a tool’s output to ensure accuracy and reduce the risk of harm.
Our experiments helped us identify one promising use case—building a chatbot to help answer navigators’ questions—which we’ll pilot with navigators.
Helping answer navigator questions
Benefit program rules and application processes are highly complex, vary from program to program and state to state, and constantly change. Navigators can spend years becoming experts in a single program, but often, applicants require holistic support from a variety of programs. Given this problem, we saw an opportunity for an AI-powered chatbot to give navigators immediate support while working through program rules with applicants.
We believed that such a tool might be able to comb through comprehensive policy guidance to answer questions about program rules. We thought this would save navigators the time spent looking up information themselves, enabling them to spend more time with applicants.
To start, we worked with navigators at Benefits Data Trust (BDT) to gather typical questions on household rules for a state’s SNAP program. We tested a range of questions, from simple ones like "Are college students eligible for SNAP?" to prompts with complex scenarios, like "The applicant has a 20-year-old child who is a college student and only lives with the client during the summer. Should this child be listed on the client's application?"
We then plugged our sample questions into a large language model (LLM) similar to ChatGPT, except instead of culling from the entire internet, our model focused on retrieving information from BDT’s internal database of state policies and program rules. When prompted with an inquiry, the model would break it down into a set of simpler questions, then it would use those questions to find relevant program rules, and finally, it would generate a response.
When we compared the chatbot’s answers to program rules, we found the chatbot’s accuracy to be highly variable and realized it would require extensive engineering to enhance. So, we decided to try a simpler approach.
The second iteration of our experiment focused on getting the model to summarize the policy information it retrieved rather than generating responses to navigators’ questions. This approach used the same retrieval method of breaking down the initial question and culling information from BDT’s knowledge base.
We hypothesized that this approach could provide the same value as our initial experiment, but with a lighter technical lift. It would also enable navigators to cite the chatbot’s source material—something that’s essential for allowing a human to verify accuracy and building trust in the tool.
Going forward, we'll continue to test the prototype using multi-benefit scenarios, adding an extra layer of complexity that’s truer to a real-life scenario. We’ll also conduct usability testing with navigators from multiple agencies to further refine how the chatbot should interact with users.
In both iterations of this experiment, we found that the accuracy of the chatbot’s output depended on how it was prompted. Given this learning, we’ll explore several methods to increase the chatbot’s accuracy, such as using the chatbot to edit and optimize navigators’ questions so that navigators don’t have to be experts in writing for an LLM. Then, we’ll pilot the tool to see how it performs in a live setting with a navigator and an applicant.
Verifying documents
Most public benefit programs require applicants to submit documents that prove their eligibility. Often, it’s confusing and overwhelming for applicants to figure out which documents to submit, especially if they are applying for multiple programs with different requirements. If an applicant submits incorrect or insufficient documentation, it can lead to delays or even denials.
To alleviate this issue, navigators review applicants’ documents before they submit them. While this is a crucial step, it’s also time-consuming and labor-intensive. That’s why we experimented to see if an AI-powered tool can automate or speed up tasks such as identifying and categorizing document types, extracting required data from documents, and providing real-time document quality feedback. We believe that such a tool could help navigators and applicants identify and address missing or incorrect documents early, avoiding unnecessary delays and denials. It might also help navigators match an applicant’s documents to program requirements and decrease the time navigators spend reviewing document details.
Our experiment focused on testing against documentation requirements for the Supplemental Nutrition Assistance Program (SNAP). We tested whether an AI-powered tool can review a document, identify what kind of document it is, and accurately extract data to determine if an applicant’s document meets SNAP requirements, such as proving one’s residency, immigration status, or identity.
We built a prototype of this tool using GPT-4o, an LLM, and found it to be promising technology for reviewing documents quickly. The tool reliably identified document types, such as a driver’s license or voter registration card, and correctly determined if various documents met SNAP requirements. Navigators and applicants gave positive reviews of the initial prototype. They said the tool would be useful for providing real-time feedback on documents, thus reducing or eliminating the time spent on documentation review.
There’s an opportunity to test GPT-4o’s technical capabilities even further to see if it can apply program rules to document categorization. For example, if a program requires a proof of identity document to include a photo, we want to see if GPT-4o will take this into account when categorizing the document.
Summarizing call notes
After speaking with an applicant on the phone, navigators must put together call notes and document follow-up steps. Currently, navigators rely on memory and the notes they take during the call to compile notes. This method can be unreliable because navigators discuss large amounts of complex information during calls while listening and taking notes. As a result, applicants may receive incomplete guidance or none at all due to the lack of recorded information. Ultimately, this can make it difficult for applicants to access benefits, and it can hinder the applicant’s trust in their navigator and in the program.
For navigators, the burden of compiling post-call notes can add to their already heavy workloads, while the pressure to complete post-call documentation can contribute to stress and burnout. Meanwhile, incomplete information can result in inaccurate documentation, causing issues with program tracking, reporting, and compliance.
Based on this problem, we saw an opportunity for an AI-powered tool that can summarize calls between navigators and applicants and provide applicants with written next steps post-call. This has the potential to improve the experience of applying for benefits, free up time for navigators, and increase the accuracy of call records for future reference and quality assurance.
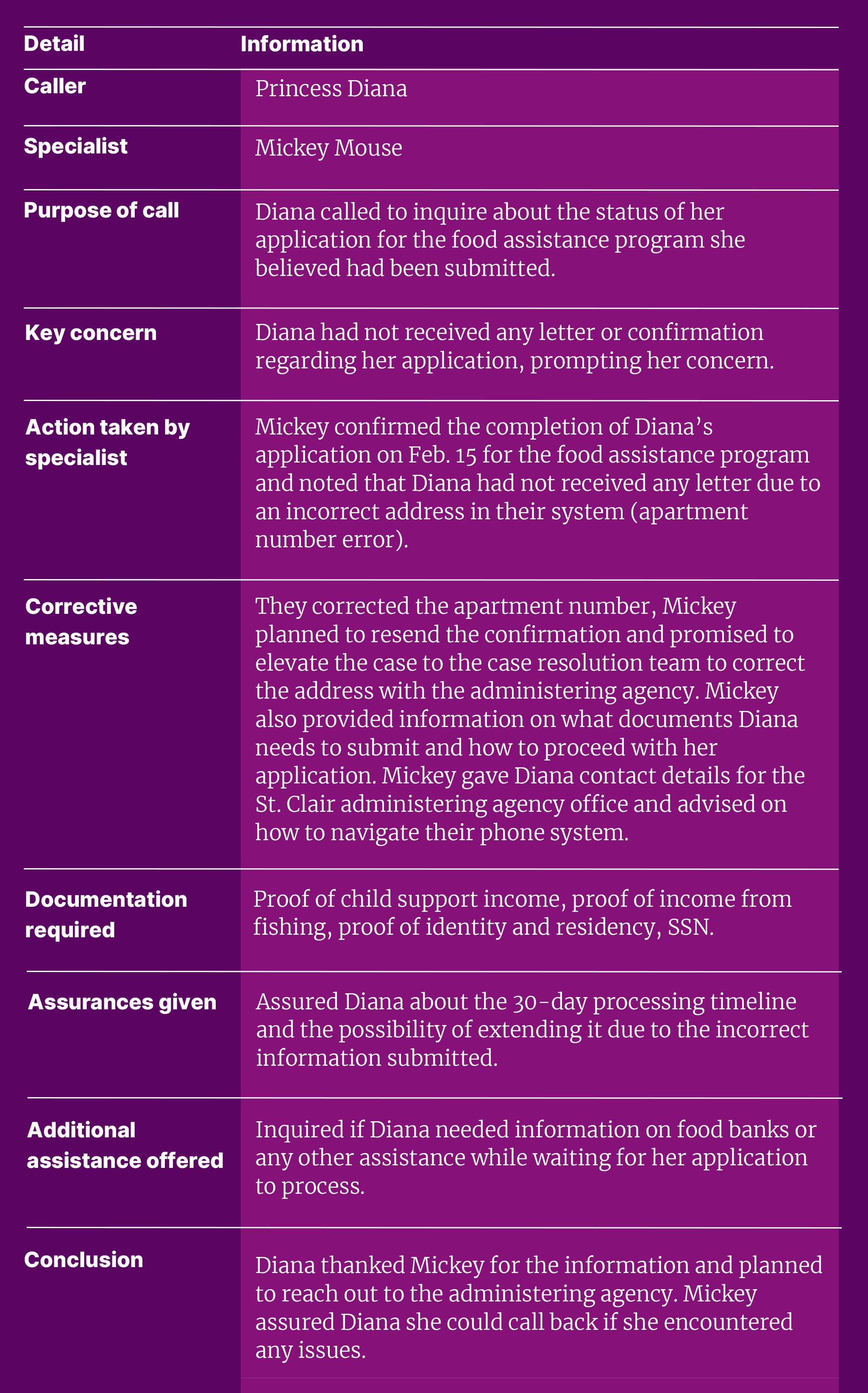
A table displaying example call notes.
To test this idea, we gave several LLMs a template and then asked them to summarize a call between a navigator and an applicant. The template specified essential information to include in the summary, such as the applicant’s key concerns and next steps for the applicant and navigator.
We tried several different summarizing techniques to determine what worked the best. The techniques were:
Stuffing, which involves feeding the entire transcript to the AI model to generate a summary. This method can offer more contextual awareness than others.
Chunking, which breaks the transcript into smaller “chunks,” summarizes each chunk separately and then combines the summaries to create an overall summary. This can be helpful for longer texts.
Refinement, which is an iterative process where the model generates an initial summary and then improves upon it. Often, the AI model will review the generated summary alongside the original text to make adjustments.
We had the most success using the stuffing technique with Gemini 1.5 and GPT 4 and 4o. This method generally worked for us because our transcripts followed a question and answer structure, but it could pose problems if a transcript contains a lot of extraneous information. We recommend skimming a transcript to see how long and targeted it is before relying on stuffing.
From testing the tool with navigators, we learned that the greatest potential value lies in the tool’s ability to save them time. Navigators and applicants also said that it would be useful for applicants to receive the AI-generated summary for their records and follow-up. Finally, we learned that navigators require different types of information and level of detail depending on their organization and role. For this reason, we recommend regularly asking navigators how useful the AI-generated summary is, and then iterating based on their feedback.
Providing referrals
People applying for public benefits often require wraparound services that can’t be addressed by a single program. This means that navigators often must refer applicants to other resources or programs in order to help meet their needs. For example, a navigator who specializes in SNAP might refer someone to another organization that can help them apply for unemployment insurance.
At BDT, navigators reference vetted, regularly updated resource lists when providing people with referrals. However, this is a highly manual process that takes time and risks missing valuable resources. That’s why we believe that an AI-powered tool may be able to help navigators retrieve referrals more quickly and thoroughly.
We designed an experiment to test whether an LLM-powered tool could provide relevant referrals when given five specific scenarios. Our tool gathered all of its referral information from a publicly available application programming interface (API) that culls data on community resources, and from mock data based on BDT’s referrals.
The API conducted simple, keyword-based searches, which caused the tool’s output to be variable. Sometimes the tool provided relevant and helpful resources, but other times it missed the mark completely. For example, the tool pulled information about Alcoholics Anonymous (AA) and a divorce education program when asked for postpartum support referrals, likely due to the keyword “support.” What’s more, it was difficult to trace where the tool got certain resources from.
Given our findings, we identified various opportunities for further exploration:
Conduct further engineering to help the tool merge results from separate databases with different formats.
Train the tool to better match needs with resources. For example, we might be able to train it to differentiate between food pantries and food assistance.
Conduct prompt engineering or ask the model to filter and analyze results returned by the API. This could prevent erroneous recommendations, like suggesting AA to someone looking for postpartum support.
Finding a way to verify referrals. For example, calling a number to ensure the organization is still operating.
Ensuring the tool cites its information so that navigators can vet referrals.
Incorporating new resources into the referral database.
Conclusion
Conducting human-centered experiments has enabled us to identify improvements and opportunities for further exploration. To start, we’re focusing on enhancing the chatbot’s ability to respond to a broad spectrum of questions from navigators and testing its performance pulling from a variety of policy sources. This will enable us to keep learning about the potential of using generative AI to streamline access to a variety of public benefit programs.
All of these use cases pose merit and value. When choosing to pursue one or more of these use cases, we recommend that agencies and organizations start by assessing their needs and capacity. Most importantly, we suggest getting feedback from stakeholders at every step of the process.
Written by

Senior policy strategist

Senior Editorial manager
