

As we build government services, shipping software with best-in-class quality and reliability is of utmost importance. A key part of delivering effective, quality software is testing to ensure that what we’re building is functioning as intended. As developers, we want to run software tests that both ensure software quality and are easy to write, understand and maintain. At Nava, we’ve leaned into modern and open-source frontend testing options to ensure seamless experiences for the constituents we serve.
In this article, we’ll review two examples of how we’ve used open-source technologies to bring human-centered testing practices to government services software.
Migrating from Enzyme to React Testing Library
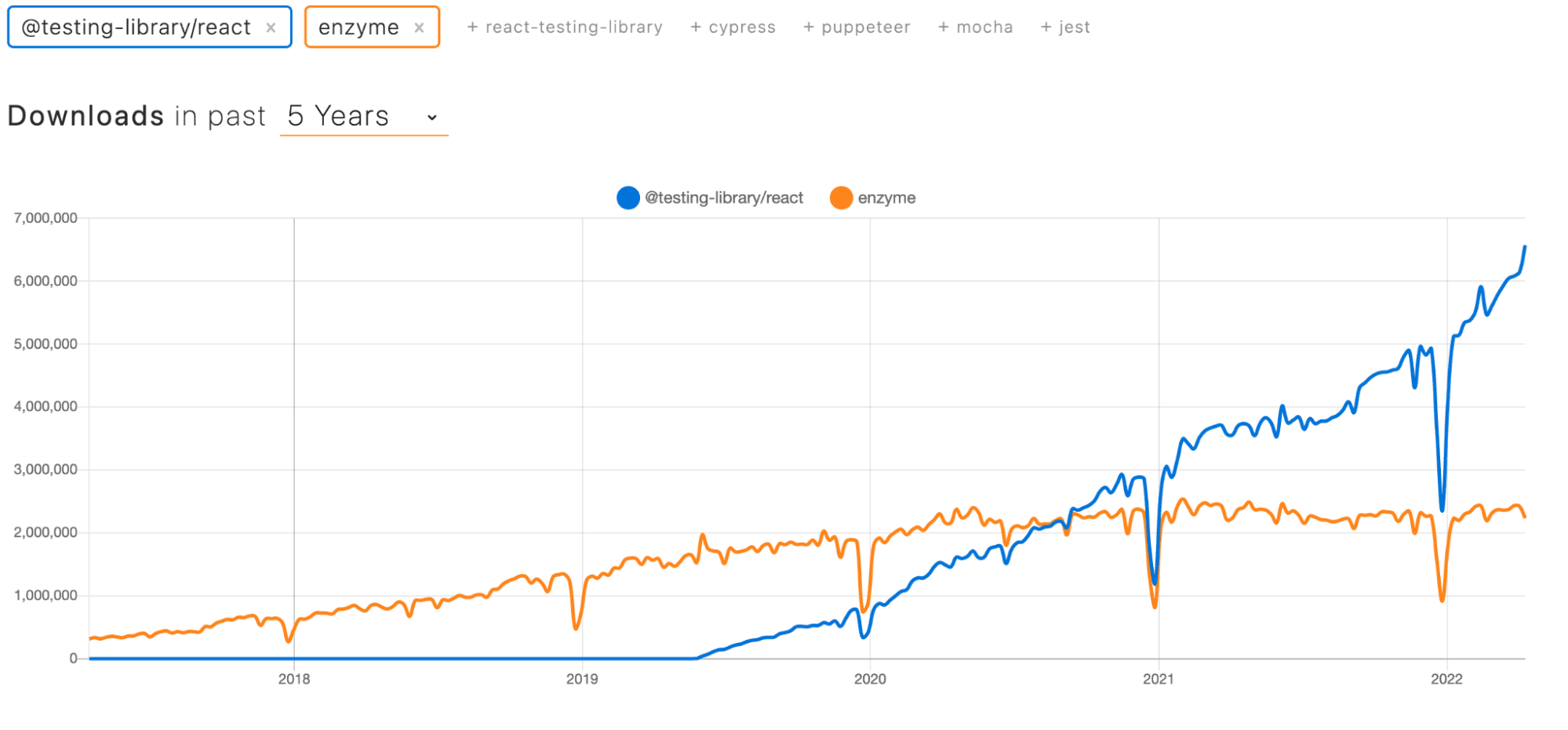
Initially, Enzyme was one of our go-to utilities for frontend testing. Enzyme is a frontend testing utility open sourced by Airbnb in 2016 specifically for React applications. For the unfamiliar, React is a JavaScript library for building user interfaces. Enzyme allows the developer to test against React component instances, meaning that you can test based on component state and props. With Enzyme, testing a shallow rendered component is also possible, meaning that you can test a specific portion of the component tree only one level deep. Our codebase used shallow rendering extensively, which allowed us to test more rapidly at the expense of testing a more complete version of the user journey through our software. In 2020, Airbnb dropped support for Enzyme. Flash forward to today and Enzyme has fallen out of maintenance.
In the Fall of 2021, our team was working on building the Commonwealth of Massachusetts’ first Paid Family and Medical Leave (PFML) program from the ground up. We realized that relying on Enzyme in the program's codebase blocked us from upgrading our React versions. We also knew we wanted to improve our accessibility test coverage. So, we began to evaluate alternative options.
React Testing Library rose to the top as a clear winner. A software engineer named Kent C Dodds created Testing Library in 2018, motivated to build something lighter-weight that encouraged better testing practices. React Testing Library surpassed Enzyme in npm downloads in 2020, and is now industry leading–React Testing Library is what the core React Team officially recommends.
React Testing Library enables us to test against the actual DOM tree rendered by the browser. In short, and crucially for us, React Testing Library enables us to test our software similar to how a human might use it. React Testing Library itself is opinionated on this, offering us this guiding principle: “The more your tests resemble the way your software is used, the more confidence they can give you.”
Diving into an example shows us this principle in action. Imagine an Accordion component that displays additional content when expanded. In Enzyme, you might write a test assertion about whether the Accordion’s state was open or closed. With React Testing Library, your test will make an assertion about whether the UI elements from the expanded section are present in the DOM. React Testing Library also encourages test writers to use the accessibility tree to find elements on the page rather than test ids, offering even more benefit in terms of verifying software accessibility.

The decision to migrate
At Nava, we build with human-centered design principles in mind. This made the shift to React Testing Library, which offers a human-centered testing approach, feel like a natural match. However, our PFML program codebase was heavily invested in Enzyme already. Would such a large migration effort and paying down necessary tech debt be worth it?
Ultimately, we decided it was worth it for two reasons:
Investment in maintainability and security: Enzyme prevented us from upgrading our React version. That meant we were unable to access new React functionality and would be unable to upgrade to address any future needed security patches. By investing in the migration to React Testing Library, we got around this issue, meaning as a team we were working with better maintained software.
Higher quality for constituents: This is a bet on human-centered testing principles. We believed that making the migration was not just a software tooling migration but a paradigm shift in our testing thinking that would improve the experience for our users.
We were able to migrate our PFML program codebase within three sprints via a dedicated, cross-scrum team engineering effort. The migration covered over 240 test suites—thousands of tests—across all areas of our frontend codebase. Throughout the migration process, we ran old and new tests in parallel to maintain test coverage throughout the effort. Completing the migration unblocked the upgrade to React 17, mitigated security risks, and brought us in line with industry standards. Perhaps more importantly, we caught multiple user-impacting bugs throughout the process. We identified UI bugs and missing accessibility labels, demonstrating to us the true value in the human-centered testing approach.
After completing the migration, we held a retrospective as a team and identified a few themes for what made the migration particularly successful:
Clear ownership: Having one engineer focusing on shepherding the effort helped us to get the effort prioritized and completed (Hat tip to the Directly Responsible Individual Framework)
Shared communication channels: This helped a large swath of engineers from different teams collaborate and stay in the know. Specifically, we created a shared Slack channel for the migration. We found that sharing updates around progress helped build momentum and enthusiasm for this engineering driven effort.
Create “golden example” tests: Before kicking off the effort, we created “golden example” tests as well as needed test runner utilities so that all engineers would have a reference as they pitched in. We agreed that documentation around testing norms and best practices was super helpful so that a variety of engineers could engage effectively. We also aligned team-wide that we would not write any additional Enzyme tests from the first day of the migration effort, and we included linting rules to enforce that.
Approval with suggestion pull request (PR) culture: We had a lot of tests to migrate but reviewing each other’s code within 24 hours and leaning towards approving with suggestions helped us keep our velocity up throughout the effort.
Alignment, alignment, alignment: In software development work, it can be hard to prioritize efforts to pay down tech debt or push for engineer-led efforts. We found that clear communication between the migration owner and leaders from other bodies of work helped us be really clear on bandwidth and how and when we’d prioritize this effort. Being organized on the engineering side so that we could push for the effort during a natural lull in the product life cycle was an additional key to helping us get the effort prioritized.
Reducing duplication by integrating Storybook and automated testing
While React Testing Library puts accessibility at the forefront and mimics how a human would interact with a web application, Storybook enables us to build and view user interface (UI) components in isolation. Storybook is perhaps most well known as an invaluable tool for component documentation, rapid prototyping, and core design system specifications. More recently (and the focus of our discussion here), Storybook has also become a foundation on which to build most automated tests for frontend components.
While creating Storybook stories is straightforward and relatively simple, there is the potential for it to feel like just yet another step on a checklist standing between a developer and the completion of a feature. We want to maximize the utility of tools like this while minimizing the burden on the development process.
Fortunately, the Storybook team has put a lot of effort into both of these facets. Recent updates to Storybook enable us to automatically generate the majority of our component unit tests based on Storybook stories we’ve already created. This is useful for developer velocity and more importantly makes it easier to deliver well-tested, accessible, and high quality software to the constituents we serve.
Using Storybook to Make Automated Testing Easier
We use Storybook extensively on our project Medicare Authenticated Experience (MAX) with the Centers for Medicare & Medicaid Services, where we are helping to design a more seamless, integrated online experience for Medicare beneficiaries.
At the beginning of this year, we had built stories for certain select components, but new ones hadn't been added for quite some time. The team —particularly the designers—knew the benefit of having everything documented in Storybook. But for engineers, the perceived overhead of writing both stories and comprehensive automated tests for all new components was an impediment. Fortunately, the Storybook team recently put a lot of effort into allowing close integration of stories and automated tests.
Using helper functions from @storybook/testing-react, we can import stories (complete with decorators, args, play functions, etc) in our existing component test files. This allows us to reuse storybook code to test different scenarios in our test files directly, saving us the work of coding scenarios in both places. Before this optimization, our developers often had to script all the same interactions in Storybook and in our tests so the ability to pull stories into our tests is a huge win.
On the MAX project, we have taken an extra step to create a helper function that, with just a few lines of code, iterates through every story and runs automated snapshot and accessibility (using the jest-axe library) tests. This greatly speeds up the process of establishing baseline automated tests when developing new functionality while reducing the burden on engineers who no longer have to duplicate their effort.
Interactivity
In addition to showing static snapshots of components, Storybook is a great way for users to see how changes—either external or internal—can affect a component. For example, a "Button" component could display one way to indicate the "primary" interaction (such as a form submission), but differently to indicate a secondary action (such as a "cancel" button). In the past, the typical way to enable this was by configuring a story to support Args. Args allow stories to override the default props for the component, and even allow the Storybook user to edit those props to see the resulting component changes in real time.
But what if—instead of changing the component's input props—we want to demo how components can change based on user actions internal to the component? Recent versions of Storybook add the concept of “play functions” that enable this.
Play functions allow us to script interactivity using the same tools (e.g. Testing Library) we already use for scripting tests. This allows us to do things like automate form filling, button clicks, or more within the story. In addition to automated testing, play functions are an additional tool in our playbook to guarantee that our software is well-tested and delivers the highest quality experience for our constituents.
Simulating API interactivity
But wait, what about connected components that make calls to APIs? For this we can mock out responses using the Mock Service Worker (MSW) add-on.
For example, a component that relies on data fetched from an API might need to conditionally display either the successful result or an error message in case of failure. With Storybook, each of these states can easily be shown as separate stories, without the need for the rest of the application to be built, or even for an API to exist yet.
This allows us to easily mock different API responses for different stories so we can, with the addition of just a few lines of code, demonstrate both a successful API request as well as an error state as separate stories. Integrating Mock Service Worker into our stories is another way we supercharge our use of Storybook to make sure we thoroughly test each path a user could experience.
What's next?
Storybook continues to push the envelope, urging not just the use of stories within tests, but actually combining stories and tests in a single place, utilizing “Interaction Testing.”
By utilizing a new test runner, one can test the assertions ("expect" calls that signify whether a particular automated test passes or fails) directly within the play function of the Storybook story.
Best of all, this can dramatically streamline the process, allowing developers to fully document and test a component, all in a single file!
In the end, our goal with both Storybook and modern automated frontend testing is to ensure that we cover all the possible scenarios a user might encounter. When this is done, all members of the project team can be assured that everything will look and act as it should to maximize the user experience, and that there will be no unexpected regressions due to future changes.
With React Testing Library and the latest Storybook functionality, we can maximize our impact while minimizing the burden on those tasked with doing the work.
Written by

Software Engineer

Senior Software Engineer
