Data engineering is a mature and widely used engineering discipline in the private sector—by making data more collectible, accessible, and usable, organizations can better unlock and utilize its potential. Nava brings data engineering approaches and experience into the government space, where better data practices have the potential to greatly impact program outcomes. For the last several years, we have collaborated with multiple vendor and government partners on the federal level to deliver data engineering and modernization efforts at scale.
By prioritizing cloud-based data infrastructure and interoperability via Application Programming Interfaces (APIs) and data pipelines, Nava has helped make data more accessible and useful. From unlocking Medicare claims data that can help providers better care for their patients to establishing data pipelines for COVID-19 tests across the nation, we’ve seen how data engineering has the potential to serve as a powerful tool in the government services space.
Using our work helping to modernize the Centers for Medicare & Medicaid Services(CMS)’s Medicare Payment Systems, this case study will explore how modernizing legacy systems by adopting cloud-based infrastructure is key to better data practices. Read more about our work building secure, interoperable data pipelines and APIs in this case study.
Summary
Medicare serves over 60 million Americans and accounts for 14 percent of the federal budget, so it’s crucial that its payment processing runs smoothly and securely. Currently, Medicare claims, provider, and beneficiary data for millions of patients sits on older mainframe systems, making claims data slow to access and difficult to scale.
Nava is a key partner in CMS’s ambitious program to shift Medicare payment processing from legacy mainframe systems to a scalable, cloud-based system. Our shared vision is to ensure that these critical systems are able to adapt to evolving Medicare policy and program needs, supporting a healthier, more equitable public.
As part of the Medicare payment modernization project, our team is building a system for transferring valuable data from mainframe systems to the cloud. We’re working to make that data more accessible, helping to unlock patient data for healthcare providers. Cloud-stored claims data has the potential to help providers improve patient outcomes while lowering the overall cost of care paid by taxpayers.
That’s because mainframe systems hold data behind decades-old code and because they rely on nightly data batch jobs, which don’t accommodate 24/7 access to the data. Cloud systems have scalable request handling baked into them, providing a modern solution for public-facing systems. That means that a doctor whose patient visits an emergency room out of state, for example, would be notified about the visit within a few days of it happening, ultimately helping the provider offer more informed care for their patient.
Approach
CMS and Nava’s shared goal is to make Medicare claims data available 24/7 in the cloud for use by other CMS applications—a feature which is not supported by mainframes. However, replicating data from the mainframe is just a first step in the process. Long term, CMS’s vision of modernization aims to process claims directly within the cloud.
Nava’s teams are supporting CMS as they build a general data pipeline to extract data out of the mainframes and inject it into the cloud. As part of this project, we helped build the Replicated Data Access (RDA) API, which makes Medicare Part A and B data highly accessible and available to a range of users in near real-time. The goal is to create new data pipelines that provide 24/7 cloud access to valuable Medicare data, even when the mainframes are offline. This would ensure data integrity with robust validation of legacy data files. Additionally, our work is helping promote the adoption of new data sources and tools by internal and external consumers with clear documentation and ongoing user support.
Outcomes
The RDA API, the first API in production to replicate Part A and B claims data from Medicare mainframes to the cloud, can ingest and stream over 20 million claim updates each day. To date, the system has successfully ingested and streamed over 1 billion claims.
Additionally, our work replicating data from the mainframe addresses some immediate issues with the existing systems:
Improved availability: The mainframes need to run batch processing jobs every night to process claims; during this time, the data on the mainframe is completely inaccessible to users who might want to view the status of claims. Cloud architecture is designed to operate off of the most recent mainframe extract, even when the mainframe itself is offline. In other words, replicating claims data to the cloud makes it accessible 24/7.
Improved reliability: Mainframe systems run into trouble when there's a spike in claims processing. By leveraging industry standard, open-source tools like Apache Kafka for traffic control, the new system organizes and queues excess load from the legacy system during a big influx of claims. This traffic control means that systems can handle ebbs and flows in claims processing.
Improved access: Mainframe systems require a single format, and can't be flexible in response to the variety of standards and formats data might use. Our cloud-based solution makes use of ingestion sinks to transform data and write it to a modern relational database. That means developers from other organizations can use new and evolving standards to build well-structured and performant APIs on top of mainframe data, but without requiring a change to the underlying mainframe structure.
Improved timeliness: Previously, external access to claims information was only available via the Common Working File (CWF) that shares claims only after 14 days have elapsed. The contracted Data Modernization Team is able to share claims as soon as they are processed on the mainframe. Those claims are then made available via a set of scalable, flexible API products that can be accessed at any time by other organizations.
Process
The Data Modernization Team accomplishes this vision by supporting several components for replication:
In order to make the closed mainframe data more easily accessible, Apache Kafka, an open-source stream-processing technology, was added to improve stream-processing. Kafka ingests data into various data storage places such as S3 files, relational databases, data lakes, and other downstream data consumers.
RDA API includes a serverless Java application that processes Medicare Part A and Part B claim records and preserves them in a database. These records are from daily extract files generated by mainframe programs. Other applications can consume this data, estimated to be more than 7 billion claims annually, via an API. The serverless application, which leverages cloud technology to offer processing flexibility, can scale up and down depending on the volume of the data, which is helpful for processing nightly batches of claims.
To make data available and flexible, we needed to define new schemas—that is, to apply a new structure to the data to bring it up-to-date with how modern healthcare systems organize their data. We defined new schemas for Part A and Part B claims data that preserve the semantic structure of claims while correcting legacy data quirks. We did this by reviewing over 2,000 claim fields and soliciting user feedback to focus on 200 fields that contained the most relevant data for care coordination. For example, our initial claim models have focused on fields to identify participants (e.g., doctors, beneficiaries), diagnosis codes, procedure codes, and indicators for specific special circumstances like ambulance rides or errors in claim submission.
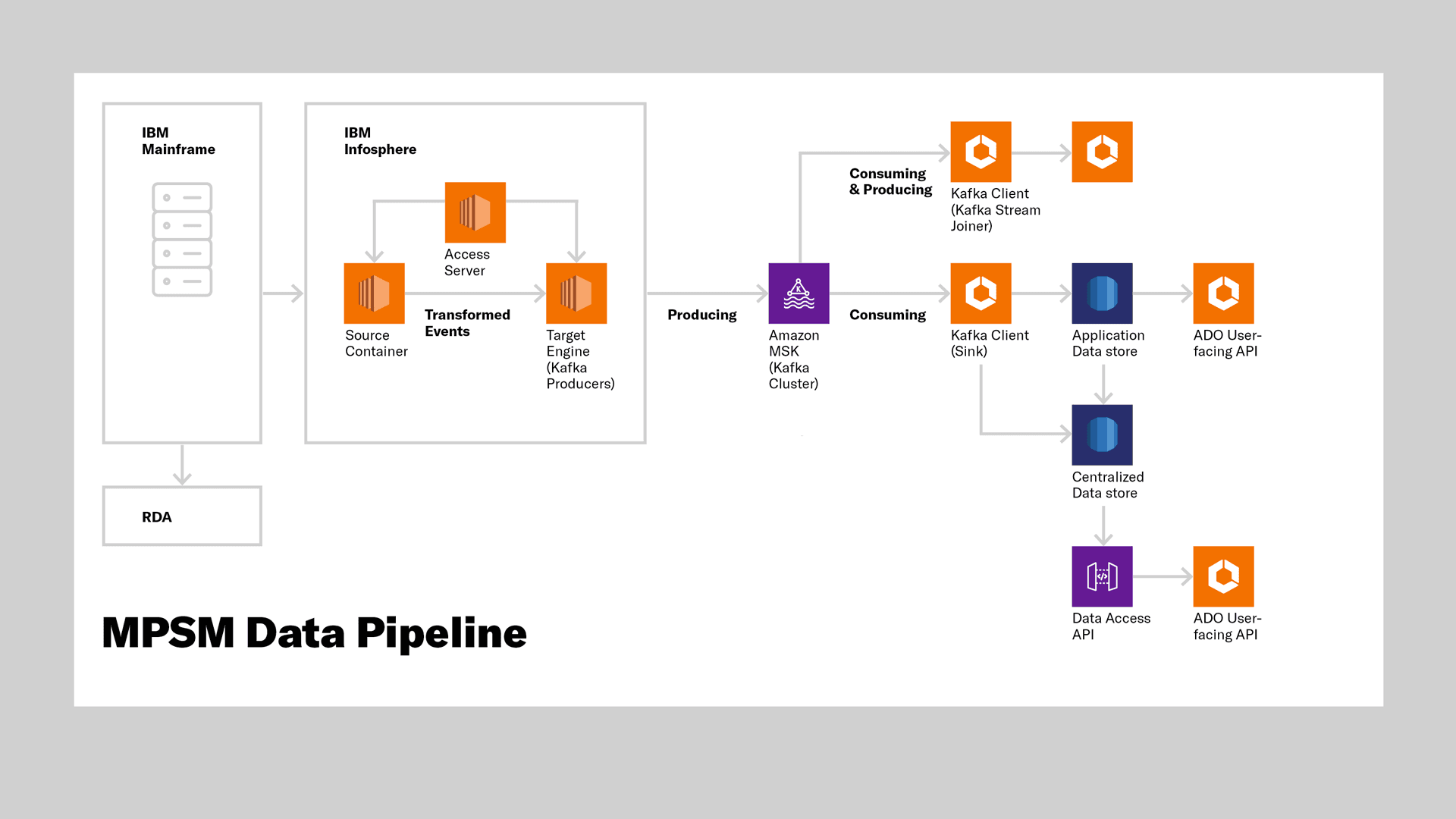
A diagram showing the MPSM data pipeline.
Our work modernizing legacy systems for CMS demonstrates the importance of mature data engineering practices for government agencies. Nava’s teams have helped build and support cloud-based data infrastructure and interoperability via Application Programming Interfaces (APIs) and data pipelines, making CMS’s public health data more accessible and useful.
Written by

Director of Engineering, Growth and Strategy
