Summary
Generative artificial intelligence (Gen AI) holds promise for improving public service delivery. However, Gen AI also poses risks that can lead to negative outcomes and erode trust with users; these include unclear information sources as well as “hallucinations,” which are AI-generated responses that are incorrect or misleading but appear as fact.
Given the far-reaching impacts of Gen AI in public benefits, our Nava Labs team is committed to researching ways to build trustworthy AI-enabled tools. We prototyped and are piloting AI-enabled tools for staff such as call-center specialists and community health workers — who we call “caseworkers” — to use when helping families identify and enroll in public benefit programs. One tool the team is focused on is an assistive chatbot that helps caseworkers get answers to questions in real time while working with families.
The Nava Labs team is working to provide caseworkers with trustworthy answers through a range of tactics. From using hand-picked source material to providing direct-source citations and more, our methodology ensures that the chatbot is human-centered, effective, accurate, and accessible. It also prioritizes minimizing the likelihood of hallucinated answers and citations. By ensuring caseworkers and the families they serve can trust the chatbot, we’re helping connect potentially eligible people to benefit programs.
Approach
In both our overall process and the chatbot technology, we used a number of tactics to improve trustworthiness of the chatbot and the answers it provides, including:
Conducting user research to inform development
Instructing the chatbot to use hand-picked source material that was vetted for accurate information
Providing direct-quote source citations
Soliciting user feedback on chatbot responses
Making use of the chatbot optional
Outcomes
Our approach appears to have been successful, with caseworkers giving encouraging feedback.
We asked caseworkers to rate how likely they are to recommend the chatbot to colleagues based on a scale from 0 to 10, with 0 being “extremely unlikely” and 10 being “extremely likely.” The median score was 8, reflecting high overall satisfaction and strong likelihood to recommend.
In interviews, caseworkers told us that our chatbot fostered trust with them in two ways: validating caseworkers’ existing knowledge about benefit programs and filling in knowledge gaps about benefit programs when they didn’t know the answers to complex questions.
One caseworker said “it is great to have something that gives you the info right away” and appreciated that “it gives you the source of where you’re getting the info from.”
In comparing our chatbot to Google, a caseworker said “I trust [the chatbot] more because Google’s going to take me here and there and Google can pull something up with information from 2020. It’s not going to be up-to-date or something I can trust.”
Process
Conducting user research to inform development
We conducted extensive, ongoing research with caseworkers and stakeholders to inform the project’s direction and specific details of the chatbot. This included over 75 research sessions with caseworkers, subject matter experts, and families.
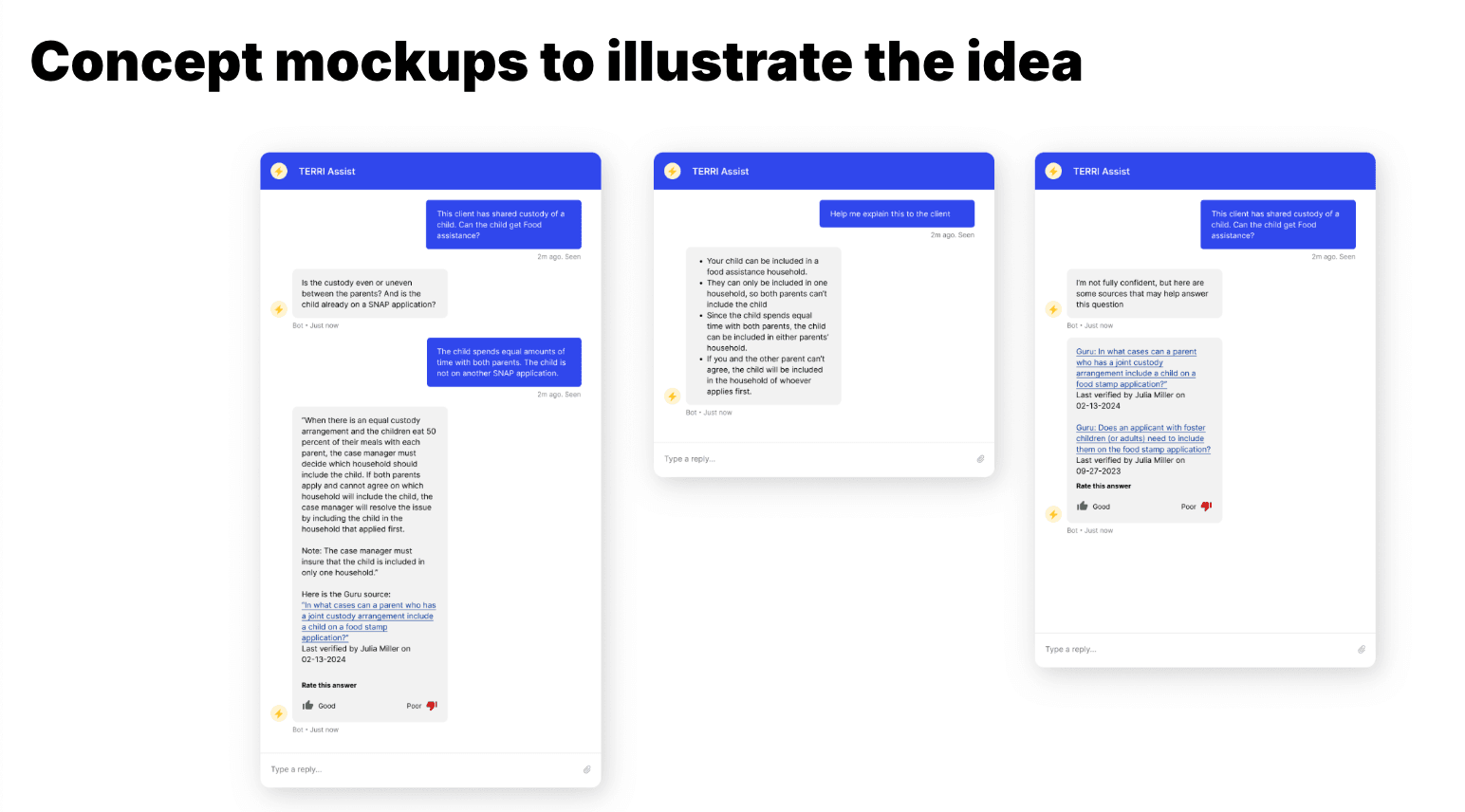
Mock-ups that we showed to caseworkers during early research to gauge potential usefulness of a chatbot (among other tools).
Engaging caseworkers throughout the development process was central to increasing our chances of building a product that meets people’s needs. Not only does this help us work more effectively, it also promotes trust among caseworkers who know first-hand how important it is to build human-centered products.
Using only hand-picked source material
Gen AI can hallucinate for various reasons. For example, developers train AI models on vast data sets that may include sources with incorrect, incomplete, or irrelevant information. Also, Gen AI models generate responses by making statistical guesses about each word they produce, which can lead to mistakes just by chance.
In our project, caseworkers are working with a specific set of benefit programs that each have rules and procedures. These rules are often state-specific, making precise details extremely important. It’s critical that we avoid providing caseworkers with information that sounds correct but turns out to be from the wrong context — such as providing someone in California with information on Medicaid application requirements in Texas.
To avoid these problems, we instruct the chatbot to write its responses based solely on the same, hand-picked set of official documentation that caseworkers are trained on.
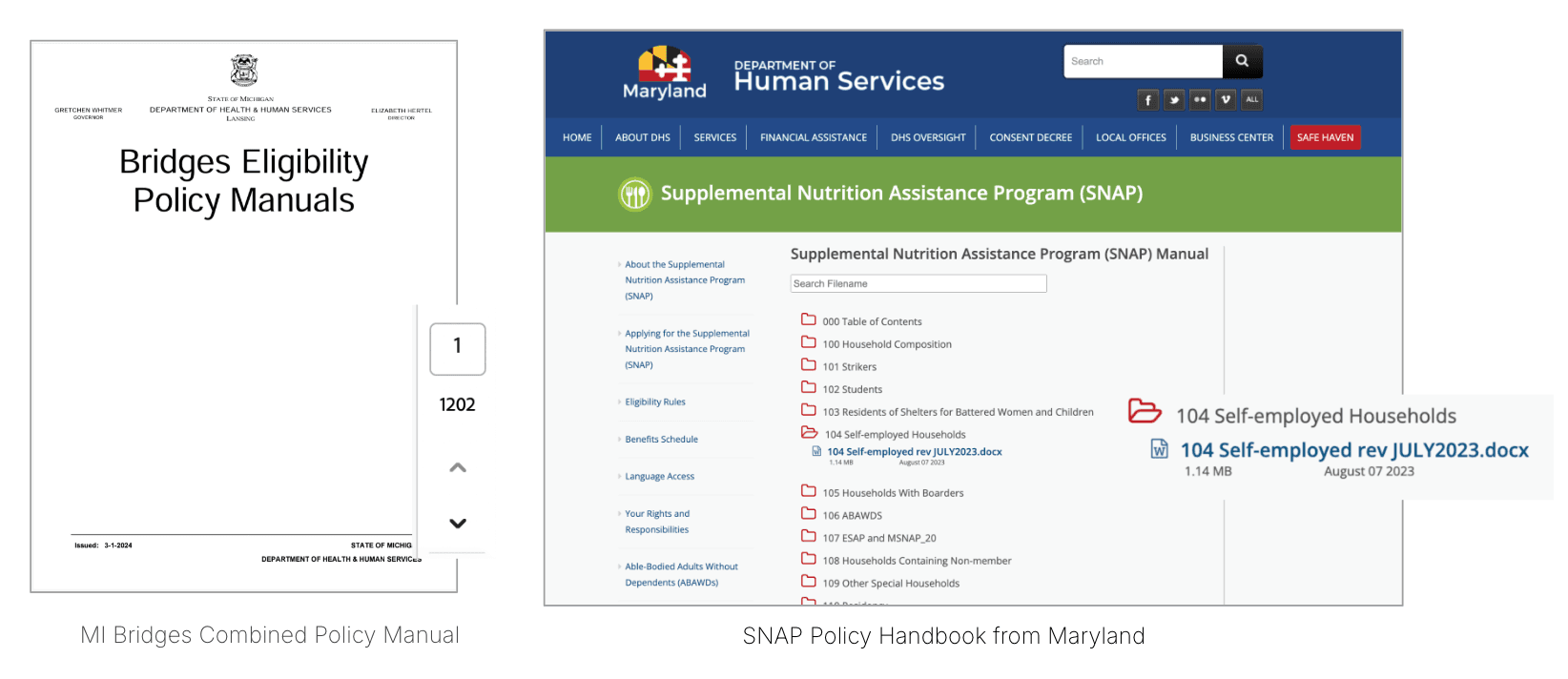
Caseworkers are trained on specific materials; our chatbot uses these same materials as its sources.
If the chatbot is not able to provide an answer based on the source documentation that we provide it with, we instruct it to say that it doesn’t know the answer rather than trying to guess an answer based on the vast range of text that it was trained on. This greatly reduces the likelihood of hallucinated answers.
Providing direct-quote source citations
In addition to providing plain-language summary answers, our chatbot also provides direct-quote citations of the source material. These citations include links so that caseworkers can see the material in context and verify it at the original source. This is an important safeguard against potentially inaccurate or misleading summaries.
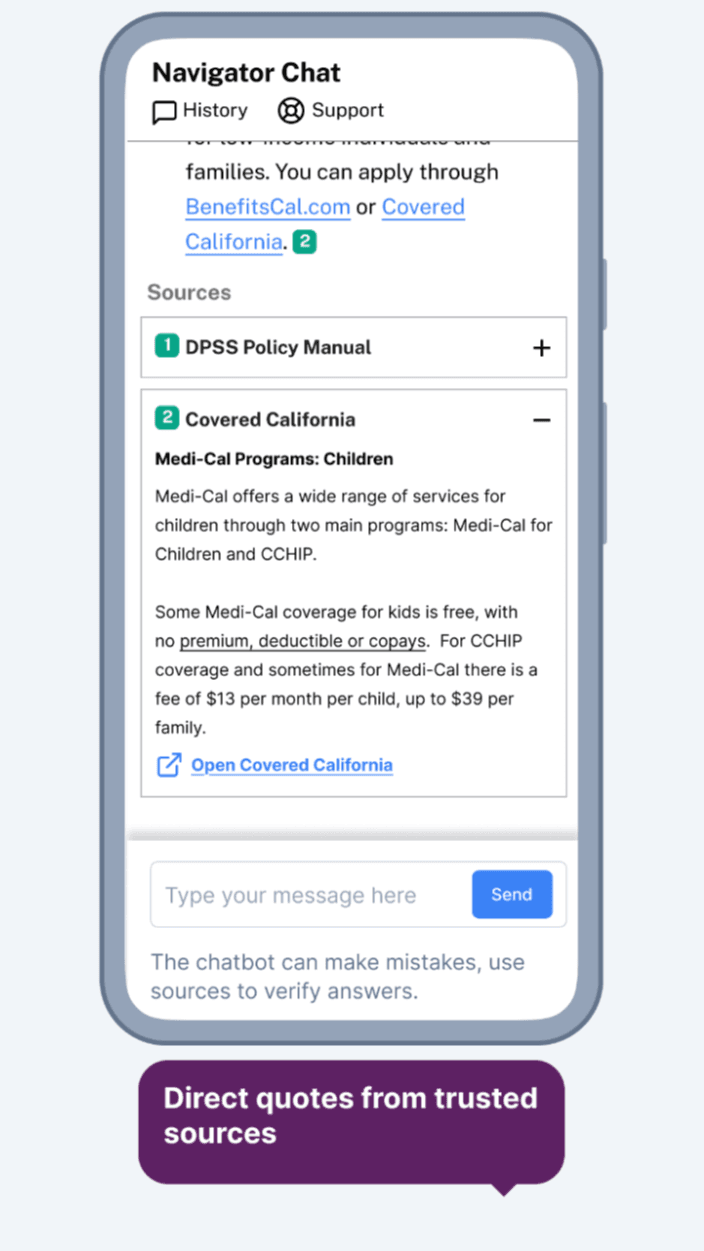
When the chatbot responds to caseworkers’ questions, it follows the summarized answer with a list of source quotes and links to the original source documents.
In order to provide the most helpful source quotes, we experimented with a series of approaches to “chunking” source data. In our experiments, we sought to balance providing caseworkers with readable quotes and providing the AI model with useful data for generating high-quality summarized answers.
A common concern with AI-generated source quotes and citations is that they might be hallucinated, such as listing a nonexistent source document. To prevent this, we do not rely on Gen AI to write the text of the source quotes and citations. Instead, after writing a summarized answer to a caseworker’s question, the Gen AI indicates which source documents (and specific paragraph numbers) it used to generate its answer, then the chatbot directly pulls that information from the source.
This method minimizes the chance of hallucinated citations.

Gathering user feedback on chatbot responses
When the chatbot provides caseworkers with answers, it also allows them to give feedback on the quality of the answer.
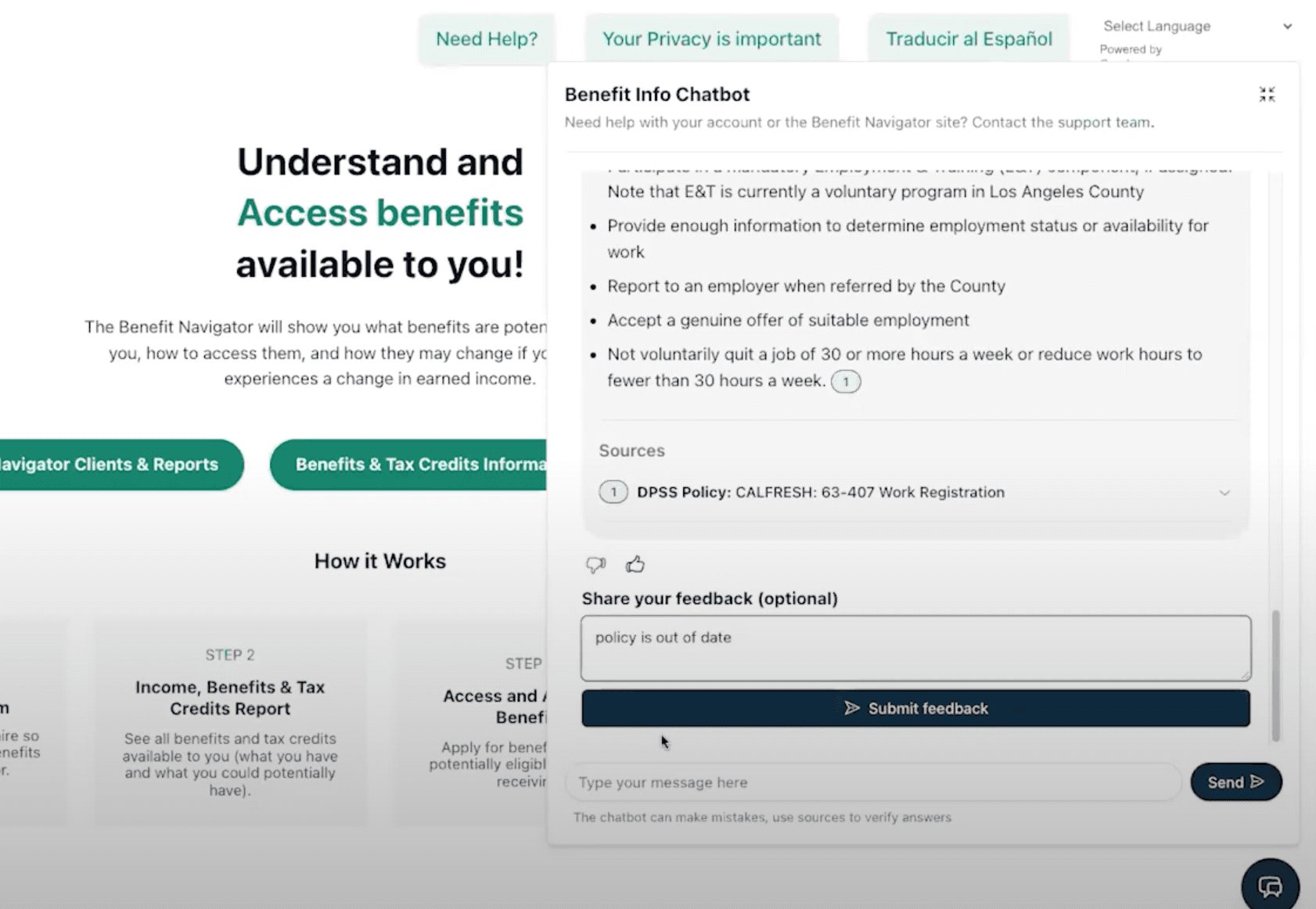
Below each chatbot response is an option to give a “thumbs up” or “thumbs down” reaction to the chatbot’s response, as well as a box for written feedback (in this case, “policy is out-of-date”). This screenshot is from the version of the chatbot embedded in the Benefit Navigator.
Our team then reviewed and analyzed the feedback that caseworkers left:

Caption: An example of an answer that the chatbot provided and the feedback comment that the caseworkers left.
This has two impacts on trustworthiness:
It helps improve trust by showing caseworkers that we care about the accuracy of the chatbot’s answers.
It allows us to see where the chatbot might be wrong, enabling us to address those issues and avoid similar incorrect answers in the future.
Making the chatbot optional to use
The caseworkers at our partner organizations are not required to use the chatbot. Instead, they can try it out on their own volition. If they choose to continue using the chatbot, it’s because they think it’s trustworthy and helpful. The chatbot’s use can also spread via word of mouth, with caseworkers who find it trustworthy recommending it to colleagues.
Conclusion
Chatbots powered by Gen AI promise to transform many organizations’ processes and workflows. However, one of the biggest barriers to adoption is a lack of trust in answers that AI chatbots provide, especially when people have seen clear examples of wrong answers, including “hallucinated” nonsense.
Our Nava Labs team takes this concern very seriously, especially in the context of trying to improve access to public services for populations in need. As such, we have carefully approached developing the chatbot to ensure that caseworkers can trust the tools we’re developing for them, delivering value in a human-centered way while protecting against hallucinations.
Our tactics include conducting user research to inform development, instructing the chatbot to only use our hand-picked source material (or otherwise say it doesn’t know the answer), backing up chatbot answers with direct-quote source citations, soliciting user feedback on chatbot responses, and making use of the chatbot optional. These kinds of trustworthiness tactics hold promise for other applications of AI to improve public service delivery.
Written by

Partnerships and Advocacy Lead

Senior software engineer
